
The continued growth of the computational capability of throughput processors has made throughput processors the platform of choice for a wide variety of high-performance computing applications. Graphics Processing Units (GPUs) are a prime example of throughput processors that can deliver high performance for applications ranging from typical graphics applications to general-purpose data parallel (GPGPU) applications. However, this success has been accompanied by new performance bottlenecks throughout the memory hierarchy of GPU-based systems. In this project, we identify and eliminate performance bottlenecks caused by major sources of interference throughout the memory hierarchy for cloud-based systems with multiple GPU and multiple concurrently running scientific and Graphics GPU applications. Specifically, we provide an in-depth analysis of bottlenecks at the caches, main memory, address translation and page-level transfers that significantly degrade the performance and efficiency of GPU-based systems. To minimize such performance bottlenecks, we introduce changes to the memory hierarchy for systems with GPUs that allow the entire memory hierarchy to be aware of applications’ characteristics. Our proposal introduces a combination of GPU-aware cache and memory management techniques that effectively mitigates performance bottlenecks in the memory hierarchy of current and future GPU-based systems as well as other types of throughput processors.
Related international publications from this project:
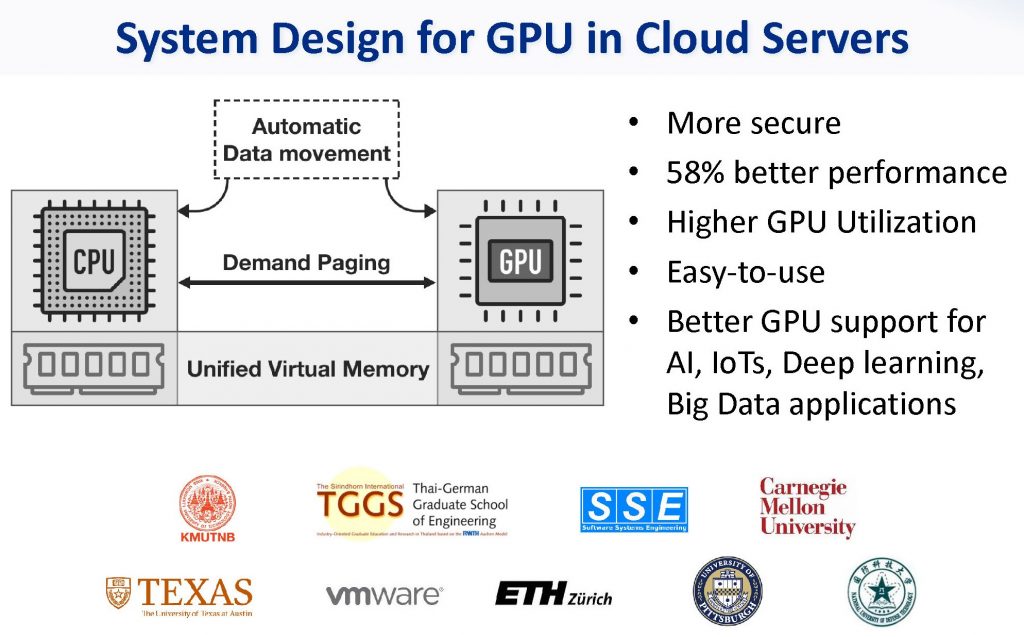
Chen Li, Rachata Ausavarungnirun, Christopher J. Rossbach, Youtao Zhang, Onur Mutlu, Yang Guo, Jun Yang, “A Framework for Memory Oversubscription Management in Graphics Processing Units”, the Proceedings of the 24rd ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS 2019), Providence, RI, April 2019.
Mohammad Sadrosadati, Seyed Borna Ehsani, Hajar Falahati, Rachata Ausavarungnirun, Arash Tavakkol, Mojtaba Abaee, Lois Orosa, Yaohua Wang, Hamid Sarbazi-Azad, and Onur Mutlu, “ITAP: Idle-Time-Aware Power Management for GPU Execution Units”, ACM Transactions on Architecture and Code Optimization (ACM TACO), December 2018.
Rachata Ausavarungnirun, Joshua Landgraf, Vance Miller, Saugata Ghose, Jayneel Gandhi, Christopher J. Rossbach, and Onur Mutlu, “Mosaic: Enabling Application-Transparent Support for Multiple Page Sizes in Throughput Processors”, In ACM SIGOPS Operating System Review – Special Topics, Vol. 52, Issue 1, July 2018.
Rachata Ausavarungnirun, Vance Miller, Joshua Landgraf, Saugata Ghose, Jayneel Gandhi, Adwait Jog, Christopher J. Rossbach, and Onur Mutlu, “MASK: Redesigning the GPU Memory Hierarchy to Support Multi-Application Concurrency”, the Proceedings of the 23rd ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS 2018), Williamsburg, VA, March 2018.
Mohammad Sadrosadati, Amirhossein Mirhosseini, Seyed Borna Ehsani, Hamid Sarbazi-Azad, Mario Drumond, Babak Falsafi, Rachata Ausavarungnirun, Onur Mutlu, “LTRF: Enabling High-Capacity Register Files for GPUs via Hardware/Software Cooperative Register Prefetching”, the Proceedings of the 23rd ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS 2018), Williamsburg, VA, March 2018.
Rachata Ausavarungnirun, Joshua Landgraf, Vance Miller, Saugata Ghose, Jayneel Gandhi, Christopher J. Rossbach, and Onur Mutlu, “Mosaic: A GPU Memory Manager with Application-Transparent Support for Multiple Page Sizes”, the Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO 2017), Boston, MA, October 2017.
More information, please click the link below:
Dr. Rachata Ausavarungnirun